

德州扑克AI -- Libratus 冷扑大师
小编前言:卡耐基梅隆大学Brown·Noam教授和他的PHD学生Sandholm·Tuomas研发的德州扑克AI Libratus(中文名”冷扑大师“)2017年底横空出世,在业界横扫了各路pro,其研究论文在2018年成为该领域年度最佳论文,我们的锦标赛课程作者徐凌老师认真研读了论文,写下了此篇读后感。在2018年的最后一天与大家分享此篇文章,祝大家新年愉快。
德州扑克被认为AI不可战胜人类
即使在Alpha Go战胜李世石之后,人们也认为短期内AI在德州扑克上是不可能战胜人类的。因为国际象棋和围棋都属于完全信息游戏,双方都可以看到对方怎么排兵布阵然后选择自己的策略,而德州扑克属于不完全信息游戏,游戏一方并不知道另一方拿着什么牌,也不知道对方采取的行动的动机是什么(是咋呼还是获取价值)。
德州扑克游戏理论上是比围棋更复杂的游戏,因为德州扑克每手牌有10的161次方种可能性,这比宇宙中的原子还要多。而围棋每局比赛有10的172次方种可能性。
之前最优秀的德州扑克AI对阵职业顶尖选手,AI每100手牌要输掉9.1个大盲注。这是非常悬殊的实力差距。
不过之前AI已经解决了罗德岛扑克(也就是手上只拿一张底牌的扑克,这游戏只有10亿种可能性,可以穷尽所有打法,所以容易解决),与限额下注德州扑克(有10万亿种可能性)。

为什么德州扑克AI开发很难
因为围棋这种完全信息游戏,之前的行动历史不会影响未来的决策。而德州扑克是不完全信息游戏,在一手牌打到转牌(第三轮下注),AI还需要返回去“思考”对手之前行动可能代表有什么牌。打到河牌(最后一轮下注),还需要根据行动再返回去修改之前的判断。而每种行动有代表非常多的可能性,这会使得寻找当前的最优解法非常困难。
这种机制使得AI不能使用人工神经网络方法,而AlphaGo使用的人工神经网络已经有很多现成的方法与工具。德州扑克AI一般使用最小后悔方法。
此外不同手牌之间历史也需要考虑,某个玩家连续做大咋呼,也许下一次更倾向于拿好牌做同样行动。或者玩家是否已经情绪失控了。(不过冷扑并没有考虑玩家每手牌之间的历史,对冷扑来说每手牌都是完全独立的。它不会知道选手之前是否在做陷阱或者已经情绪失控了)
冷扑VS职业选手
2017年1月。冷扑挑战4位世界顶尖人类德州扑克单挑选手,他们每人在20天内与冷扑游戏了12万手牌。比赛结束时,冷扑一共赢了170万美元,平均每100手牌赢14.7个大盲。在同年4月卡内基梅隆大学校友李开复携冷扑,与由中国德州扑克高手组成的龙之队在海南比赛,冷扑再次获得巨大胜利。
冷扑的诀窍
冷扑的诀窍是:在每手牌,每一轮下注寻找纳什均衡打法,也就是我们俗称的GTO打法。通过自己严格按照纳什均衡打法游戏,其他玩家只要偏离了最优均衡打法,它就肯定会受到损失。数学证明在扑克单挑游戏中只要坚持纳什均衡打法,就能保证盈利(除非对手也按纳什均衡来打),所以冷扑并没有针对其他游戏玩家的风格来改变打法,它只是按自己节奏打。注意以上结论只适合于单挑游戏,不适合于多人桌游戏以及锦标赛。
以下内容如果对冷扑系统不敢兴趣可以选择跳过…
冷扑系统分为3大板块
1. 抽象化扑克游戏,也就是缩减扑克游戏复杂度。然后使用最小后悔算法寻找纳什均衡打法。
2. 细分博弈。 这个系统是为了寻找在计算出来的一堆博弈情景中,AI和玩家处于哪种博弈情景之中。
3. 自我进化。通过分析一整天的比赛数据与玩家的策略,寻找并修复自己的游戏漏洞,使得第二天比赛更完美。
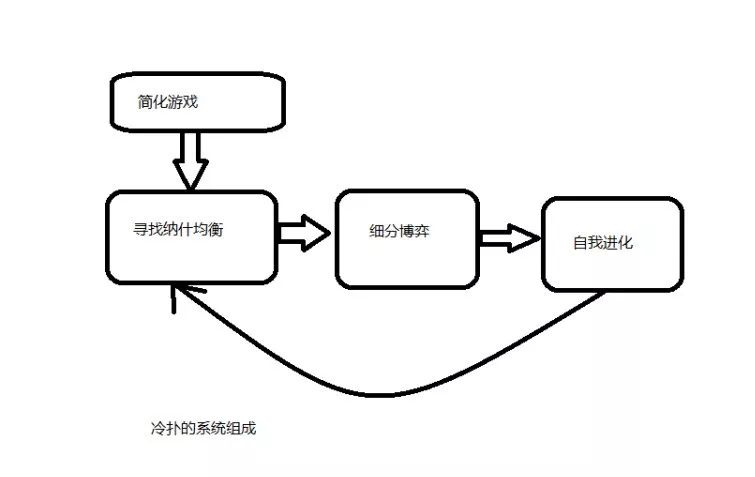
具体实施
Alpha Go的行动是根据对手的行动实时计算的,因为不可能让AI记住所有的可能场景。但是一般德州扑克AI的办法不一样,因为实时计算的计算量庞大,但是AI遇到的场景种类比围棋少。所以冷扑和其他德州扑克AI的主要打法都是事先算好的,比赛时拿到什么牌,对手怎么行动很大程度是靠着之前算好的游戏行动规则执行就好了。不过要让AI知道当前处于什么博弈情形是一大难点。
首先,一般AI都会缩减德州游戏的复杂度,德州扑克有10亿种牌型组合,但是不少游戏牌型其实是一样的,比如5红桃6黑桃其实和5方块6梅花没什么区别。之前德扑AI把A黑桃5梅花和A红桃5方块这样的牌也归为一类,这就有些危险。因为在3个黑桃牌面中,前者是阻断牌,后者不是两种牌的打法其实并不一样,用前者去咋呼更可行。这里冷扑做了改进,使得决策更科学。
一般的德州扑克AI也会将玩家下注额度进行四舍五入,比如你下注101元和下注100元在AI眼中是一样的。这种下法有时候会有非常大的潜在漏洞,很多聪明的玩家都会利用AI的这个漏洞剥削AI,我们后面再解析。
冷扑对前两个下注轮(翻牌前和翻牌后)手牌牌型不做任何缩减,也就是5红桃6黑桃其实和5方块6梅花是不同手牌。这两轮中冷扑计算对手10种下注大小。而且这两个下注轮,冷扑的行动会完全按照自己之前算好的游戏行动一览表游戏,不会做实时计算。
 ▲ 冷扑的机房
▲ 冷扑的机房
冷扑对后两轮下注(转牌与河牌圈)手牌进行很大的缩减。一个是上面提到的牌型缩减,另外它只把对手的下注简单归类为2到3种下注类型。后面这两轮,冷扑只利用行动一览表计算EV(刨除运气成分的盈利),并不利用行动一览表来指导具体操作。这样做是为了减少计算量,因为翻牌前和翻牌圈(前两轮下注)都是预先设计好的,但是后两轮下注如果场景太多,会让计算难度指数增长。
经过这样的简化,冷扑每手牌的计算量为5万G大小。(看来在自己家电脑跑一个冷扑是不可能的了)

其次,在缩减了游戏复杂度后,AI利用一种叫做“蒙特卡罗虚拟事实模拟后悔最小化”(MCCFR)的算法,来计算纳什均衡。
具体算法就不详细解释了,免得文章太无聊。这算法大致有点像人类讨论牌局,打个比方:我拿了AK翻牌前平跟,在带A的翻牌下了注,河牌出了同花面,面对别人下注,我选择all in结果对手拿同花跟注,我输掉了牌局。
事后我后悔说:我应该翻牌前加注10个大盲,而不是平跟。
对手说:那你下10个大盲,我翻牌就fold掉咯,你也没拿到什么价值。
我再后悔说:那我翻牌加注3个大盲,你call,我翻牌下重注保护,你肯定弃牌。
这样每次把后悔降到最低,对手针对自己的改动再做改动,一次次推演,最后达到一个自己的最优方案。
这个算法本身不是冷扑发明的,但是冷扑改进了这个算法,把一些明显不合理的打法排除在外,比如拿27非同花这种最弱的牌翻牌前加注或者拿AA这种强牌翻牌前弃牌。如果某种打法一直都是负EV,那么之后冷扑会越来越少地去考虑这种打法。之前的德扑AI会反复考虑这种不合理打法,从而挤占了大量的计算资源。有数学论文证明刨除这种不合理打法并不影响纳什均衡的正确性。通过这种改进,冷扑计算纳什均衡的速度提升了100多倍。
第三,之前的德扑AI会利用贝叶斯法则(一种概率反演算的定律)来推断对手的手牌范围,这种办法会导致AI产生极大的漏洞。冷扑用的办法是不预先假定对手的手牌范围,而是考虑对手如果拿着某手牌做出这样的行动合理不合理,按照他自己的纳什均衡,这样的动作会让他损失多少EV,从而调整自己的行动最大化对手的损失。
举个例子,这也是一般人类和AI很棘手的问题。一个人上桌第一手牌就翻牌前推了你200个盲注,你拿A9同花应该跟注还是弃牌。一般人类和之前的德扑AI往往会推测对手手牌范围,然后考虑平均来说跟注值不值得。推测对手手牌范围的行为会让自己打法产生漏洞,容易被高手钻空子。冷扑利用了2014年发明的一种新算法,他不推测对手平均手上拿什么牌,而是针对每种手牌考虑:假如对手拿27它应不应该全压,如果按照他自己的纳什均衡策略,他全压27损失巨大。那如果他拿AA应不应该全压,按照他的纳什均衡策略,AA全压太浪费了,损失也是巨大。一个一个的考察他每种手牌这样打会损失多少EV。然后我们选择一种打法让他长期来说损失EV最大的打法。也就是说,你可以每把拿烂牌推我,但是万一我拿到好牌call你,你损失巨大。所以我不怕你这样打。(注意冷扑不会考虑之前玩家游戏历史,所以连续翻牌前推10次和翻牌前推1次对冷扑是一样的)
第四,之前德扑AI会把对手的下注大小简单的四舍五入,这是一个大漏洞,一来会导致纳什均衡计算出错,二来会导致人类利用AI这点来剥削AI。冷扑的做法是如果人类做出了不寻常的奇怪下注,冷扑不会简单的四舍五入,而是会针对这种下注方法独立的展开纳什均衡计算。他们的实验发现,使用这种算法,可以让冷扑被人类高手剥削的可能性降低为原来的1/12. 但是这个方法只用在转牌和河牌圈(后两轮)前两轮还是简单四舍五入。
最后,也是让冷扑变得强大的一个重要系统,就是冷扑能总结一整天下来的游戏,修补自己的漏洞。它会优先考察自己最常见的错误,每个晚上冷扑大概能修补自己3个漏洞(其实还有更多漏洞,不过电脑的计算量限制下冷扑只能修补两三个漏洞)。
冷扑的弱点
开发者承认冷扑最大的弱点是不会考虑对手打法。就算你从来不咋呼,或者每手牌都咋呼,冷扑以及现在主流的德扑AI都不会利用你的漏洞。德扑AI只会坚持纳什均衡打法,利用人类偏离纳什均衡的错误来盈利。这点和人类玩家很不一样。
冷扑即使在晚上的自我进化阶段也不会去寻找人类的漏洞。
不过开发者说,这个弱点也恰好同时是冷扑的优点。因为假如你要去剥削对手的弱点,那么你自己就会卖出破绽,这样人类高手反而会利用你的破绽来剥削你。比如你看对手把把咋呼,下一把你想着要去抓对手咋呼,那你必然会拿弱牌跟注对手。这时你自己就卖了个漏洞出来,对手有可能利用这个漏洞来反打你。而抓漏洞的游戏上,AI肯定玩不过人类高手。真正好的打法是不管对手有没有漏洞,AI寻找纳什最优打法的能力肯定比人类强,只要AI按照最优打法来打,人类一犯错,AI就能盈利。
事实上人类顶尖高手的明显漏洞非常小,AI尝试去抓人类漏洞是危险的行为。AI和普通人类玩家交手也能取得很大的优势。但是剥削弱玩家的能力上,AI是比不过人类高手的。(不过反正坚持按照GTO(最优打法)玩都能赢,为什么一定要想着去剥削对手呢)
此外很多人类以为AI会侦查他们的漏洞,所以故意卖漏洞给AI,这也造成了他们进一步偏离纳什均衡,反而承受更大的损失。

从冷扑学到的技术
跟冷扑交战过的人类高手普遍认为,冷扑的操作非常像强大的人类打法,但是却时不时做出出人意料的行动。人类顶尖高手认为,冷扑的一些策略绝对会影响未来人类的德州扑克打法。
多样化的下注大小。一般人类倾向于下注半个底池,2/3个底池这样一两种下注额度,以免被别人破解出下注习惯。但是冷扑可以做出5到10种下注模式,这样对手很难适应。不过这样打法对人类来说很难平衡。
反主动下注,也就是俗称的donk bet。一般人类都认为做donk bet是扑克新手的打法,是一种错误的操作。但是冷扑发现donk bet是一种很有效的打法,可以有效阻挡对手听牌和持续下注。但是同样地,平衡很重要。
超底池下注。这种行为以前也被认为是鱼的打法,一般职业高手很少做超底池下注,顶多就是一个底池的下注。偶尔做出超底池下注也顶多是1个半底池的下注。但是冷扑的超底池下注非常变态,在1000刀的底池冷扑敢下注1万刀甚至2万刀来抢底池。甚至在一个仅仅200刀的底池,冷扑会直接下注2万刀。这种打法让人类非常痛苦,一些超额下注经常会让人类高手思考10分钟都无法做出决定。他们也经常会扔不掉自己第二好的牌,错误地跟注。自从冷扑之后,在高端德州扑克牌局,人类高手已经越来越多地使用到超高额下注的技术。(这个技术很危险,新手不要乱学,否则变送钱了。)
平衡打法隐藏自己牌力很重要。
冷扑的打法是否是真正的纳什均衡或GTO打法呢?
其实不是,因为寻找纳什均衡的计算量超出了现在的超级电脑的能力。冷扑的打法只能算接近纳什均衡。他们理论估算真正的纳什均衡打法每100手能赢冷扑5个盲注。(冷扑赢人类高手14.7个盲注/100手)
最后,冷扑其实不是凭空产生的,德州扑克AI是世界上人工智能研发的一个热点,已经有20多年研究历史。冷扑的大部分算法其实都是站在前人的基础上的。德州扑克AI的理论知识大部分来自于博弈论,而据说世界上近20年来博弈理论的理论研究,几乎都是在研究德州扑克。博弈理论之父冯·诺依曼创立博弈论的初衷也是为了打德州扑克。所以冷扑的开发离不开其他科学家,数学家的研究。
为了写这篇文章,论文里有不懂的地方,我发邮件给冷扑的开发者布朗提问,本来没想到他会回信,他竟然还拨冗回信了,还写了很长篇幅的一副回信,太感谢了。
这次篇幅有点大,下期预告: 下期会讲讲卡内基梅隆大学的冷扑AI开发团队认为近期内有没有可能开发多人桌德州扑克AI,他们认为什么游戏比德州扑克和围棋AI,星际争霸AI更具挑战性呢? (我都没想到这种游戏竟然他们会觉得很难开发能战胜人类的AI,大家猜猜是什么)






